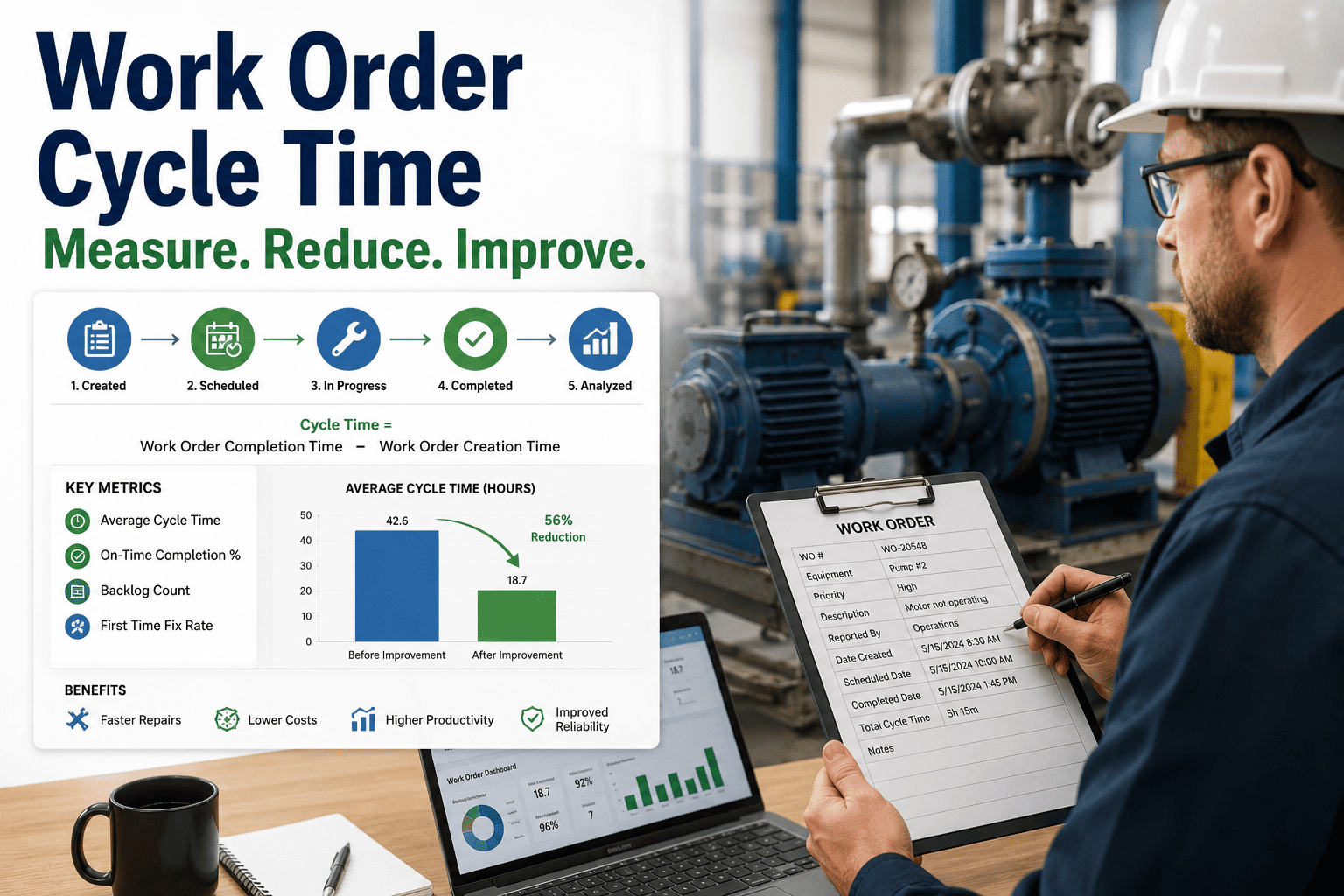
Your maintenance director walks into Monday's executive meeting with cautiously optimistic news: "Our predictive maintenance pilot on Line 3 achieved 92% failure prediction accuracy and prevented $450,000 in unplanned downtime over six months." The CFO immediately asks the obvious question: "When can we deploy this across all 27 manufacturing sites?" Your director hesitates, then admits: "We've been stuck in scaling discussions for eight months—integration challenges, data architecture issues, and governance concerns keep blocking enterprise deployment." You're trapped in what industry experts call "pilot purgatory"—successful proof-of-concept forever confined to isolated implementations while competitors achieve facility-wide predictive maintenance transformation.
This frustrating scenario unfolds across American manufacturing as facilities struggle to scale GenAI and predictive maintenance pilots beyond initial successes. Industry research reveals that 80% of industrial AI projects never progress past pilot stage, wasting $2.3 million average investment per failed scaling attempt while organizations miss out on $8-15 million in potential enterprise-wide benefits.
Manufacturing facilities that successfully scale predictive maintenance AI achieve 45-65% reductions in unplanned downtime across entire operations while improving maintenance efficiency by 35-50% compared to those trapped in pilot purgatory. The transformation requires understanding architectural requirements, governance frameworks, and systematic scaling methodologies that move pilots from isolated successes to enterprise-wide deployment generating millions in sustained value.
Ready to escape pilot purgatory and scale your predictive maintenance AI across all facilities?
Every month your AI stays confined to pilots costs $200,000-500,000 in missed optimization opportunities. The 30-60-90 scaling blueprint that transforms isolated successes into enterprise-wide ROI machines is proven—discover the exact architectural frameworks and governance strategies that move 92% accuracy pilots into facility-wide deployment.
Revolutionizing Manufacturing with Local AI
Join us for a live demonstration showcasing how local AI deployments powered by NVIDIA GPUs and LLMs are solving the exact scaling challenges discussed in this article. See real-time predictive maintenance processing thousands of sensor signals in seconds—all without cloud vulnerabilities.
Limited seats available • Watch manufacturing AI transformation in action
Why 80% of GenAI Projects Fail to Scale in Manufacturing
Understanding the systemic barriers preventing predictive maintenance pilot scaling requires examining the fundamental disconnects between proof-of-concept success factors and enterprise deployment requirements. These obstacles extend far beyond technical performance metrics to encompass architectural limitations, organizational readiness gaps, and governance framework deficiencies that systematically derail scaling initiatives.
The pilot purgatory trap emerges from a critical misconception: organizations assume technologies proving successful in controlled pilot environments will automatically succeed at enterprise scale. Reality proves dramatically different—pilot implementations typically operate in carefully curated data environments with dedicated resources and simplified integration requirements, while enterprise deployments must navigate legacy system complexity, data quality variability, and organizational resistance across dozens of facilities.
Industrial AI scaling failure stems from three primary architectural deficiencies rather than algorithm performance issues. First, pilots frequently rely on manual data preparation and feature engineering sustainable for single-line implementations but impossible to replicate across 20+ manufacturing sites. Second, brownfield system integration challenges—connecting AI platforms with decades-old SCADA systems, disparate sensor networks, and incompatible data formats—prove exponentially more complex at scale than pilots suggest. Third, governance frameworks sufficient for isolated pilots completely inadequate for enterprise AI deployments requiring data quality standards, model versioning protocols, and cross-functional accountability structures.
Data Architecture Fragmentation
Pilot success with clean, prepared datasets masks enterprise reality of 15-40 incompatible data sources per facility. Scaling requires unified data pipelines processing 50-200 TB monthly across heterogeneous systems.
Integration Complexity Explosion
Single-line pilot integration takes 200-400 hours. Enterprise deployment across 25 facilities requires 8,000-15,000 hours without repeatable integration frameworks and API standardization.
Cloud Dependency Vulnerabilities
Cloud-based AI requires constant connectivity, creates data sovereignty concerns, and adds latency. Local AI deployments on NVIDIA GPUs process sensor signals in real-time on-site, eliminating cloud bottlenecks.
Organizational Change Resistance
Pilot teams embrace AI innovation. Enterprise rollout encounters maintenance technicians skeptical of algorithm recommendations, requiring comprehensive training and change management for 200-800 personnel.
Model Drift and Maintenance
Pilots manually monitor model performance. Enterprise AI requires automated drift detection, retraining pipelines, and governance ensuring 50+ deployed models maintain 85%+ accuracy continuously.
Real-Time Processing Requirements
Local LLMs analyzing thousands of sensor signals in seconds enable instant predictive maintenance decisions. Cloud architectures introduce 200-800ms latency preventing time-critical interventions.
Financial analysis reveals pilot economics versus enterprise deployment economics differ dramatically, creating ROI calculation challenges that undermine executive support. Pilots generating $450,000 annual value with $180,000 investment appear highly attractive, but enterprise scaling requiring $3.2 million infrastructure investment to realize $8-12 million total benefits creates approval barriers when organizations fail to articulate comprehensive scaling business cases.
Technology selection decisions made during pilot phase frequently constrain scaling potential. Point solutions optimized for rapid pilot deployment often lack enterprise features like multi-tenant architecture, role-based access control, and API management capabilities essential for facility-wide implementations, forcing expensive platform migrations or compromised deployments limiting ultimate value realization.
Architectural Failures vs. Model Quality Issues
Distinguishing between model performance limitations and architectural deficiencies represents the critical first step in diagnosing scaling barriers. Organizations trapped in pilot purgatory typically misattribute scaling failures to algorithm accuracy issues when root causes actually stem from data infrastructure inadequacy, integration architecture gaps, and deployment framework limitations preventing reliable model execution at enterprise scale.
Model quality assessment reveals most successful pilots achieve 85-95% prediction accuracy sufficient for enterprise deployment. The scaling barrier emerges not from algorithm performance but from inability to consistently replicate training data quality, feature availability, and inference latency across diverse manufacturing environments. A pilot achieving 92% accuracy on Line 3 with 50ms inference latency may degrade to 68% accuracy with 800ms latency on Line 17 due to sensor configuration differences, network bandwidth constraints, or data preprocessing pipeline variations.
| Scaling Barrier Category | Pilot Phase Impact | Enterprise Phase Impact | Resolution Approach |
|---|---|---|---|
| Data Pipeline Architecture | Minimal—manual data prep acceptable | Critical—requires automated ETL for 20+ facilities | Build unified data fabric with standardized schemas |
| Model Deployment Framework | Low—single model manually deployed | Essential—50+ models need automated versioning | Implement MLOps platform with CI/CD pipelines |
| Integration Patterns | Moderate—direct API connections work | Severe—requires message bus, queue management | Deploy enterprise service bus with standardized APIs |
| Monitoring and Governance | Low—manual performance tracking sufficient | Critical—automated drift detection mandatory | Establish model observability and governance framework |
| Change Management | Minimal—pilot team self-motivated | High—200-800 technicians need training | Deploy comprehensive training and support infrastructure |
Brownfield system integration challenges represent the most underestimated scaling barrier in manufacturing AI deployments. Modern predictive maintenance platforms assume cloud connectivity, RESTful API availability, and standardized data formats, while manufacturing facilities operate 15-30 year old automation systems using proprietary protocols, isolated networks, and incompatible data structures. Successful scaling requires middleware layers translating between legacy OT systems and modern AI platforms—infrastructure investments often exceeding algorithm development costs by 3-5x.
Repeatable success patterns emerge from analyzing facilities successfully scaling predictive maintenance AI across multiple sites. These organizations establish technology stacks prioritizing standardization over customization, deploy common data models enforced across all facilities, implement automated testing validating model performance before production deployment, and create center-of-excellence teams providing scaling expertise rather than allowing site-by-site custom implementations fragmenting architecture and multiplying support complexity.
Edge computing versus cloud deployment decisions significantly impact scaling complexity and cost structures. Centralized cloud deployments offer simplified model management but require network bandwidth and latency tolerances many manufacturing facilities lack. Edge deployments enable local inference with minimal connectivity requirements but complicate model versioning and create distributed management challenges across 20-50 edge nodes requiring synchronized updates and performance monitoring.
Local AI deployment architectures—utilizing on-site LLMs running on NVIDIA GPUs—are emerging as the optimal solution for enterprise predictive maintenance scaling. These systems process thousands of sensor signals in real-time directly on the factory floor, eliminating cloud latency and data transfer bottlenecks while ensuring sensitive manufacturing data remains behind facility firewalls. Local AI addresses three critical scaling barriers simultaneously: integration complexity (direct connection to existing SCADA and ERP systems), data security compliance (no cloud vulnerabilities or data sovereignty concerns), and real-time performance requirements (sub-second inference for time-critical decisions).
The local AI architecture also resolves the brownfield integration challenge that derails 60-70% of cloud-based scaling attempts. Rather than requiring complete OT/IT infrastructure modernization, local deployments leverage existing sensor networks and control systems through standardized integration layers. Organizations implementing local AI strategies report 40-50% faster deployment timelines and 30-35% lower total cost of ownership compared to cloud-dependent architectures requiring extensive network upgrades and ongoing data transfer costs.
Governance Frameworks for Enterprise AI Integration
Establishing comprehensive governance frameworks before enterprise AI scaling prevents the organizational chaos, accountability gaps, and quality degradation that systematically undermine deployment value. Governance encompasses far more than compliance checklists—successful frameworks define data quality standards, model performance thresholds, change control procedures, and cross-functional accountability structures ensuring AI deployments maintain effectiveness while adapting to evolving operational requirements.
Data governance represents the foundational layer enabling predictive maintenance scaling. Organizations must establish data quality standards defining acceptable sensor calibration tolerances, missing data thresholds, and outlier detection protocols applied uniformly across all manufacturing sites. Without standardized data quality enforcement, AI models encounter training-inference distribution mismatches causing performance degradation—the primary reason pilot accuracy of 92% collapses to 68% in production environments.
Enterprise AI Governance Framework
Model lifecycle management protocols prevent the technical debt accumulation that transforms innovative AI deployments into unmaintainable systems requiring expensive rebuilds. Governance frameworks must mandate version control for all models, automated testing validating performance before production deployment, rollback procedures enabling rapid response to degraded performance, and documentation standards ensuring model logic remains understandable as personnel change over 3-5 year deployment lifecycles.
Cross-functional accountability structures prove essential for scaling success. Successful governance frameworks designate model owners responsible for ongoing performance, data stewards ensuring input quality, integration specialists maintaining system connections, and business stakeholders defining success metrics and ROI targets. Without clear accountability, AI deployments drift into orphaned systems no team fully owns or actively optimizes.
The 30-60-90 Day Scaling Roadmap
Systematic scaling requires structured implementation roadmaps transforming pilot successes into enterprise deployments through phased rollouts that manage risk, incorporate learning, and build organizational capabilities progressively. The 30-60-90 day scaling framework provides battle-tested blueprints enabling manufacturing organizations to move from single-line pilots to facility-wide deployments while maintaining operational stability and demonstrating incremental value justifying continued investment.
Days 1-30 focus on scaling readiness assessment and architecture preparation. Organizations must conduct comprehensive data infrastructure audits identifying standardization requirements across facilities, evaluate integration complexity for each manufacturing site, assess organizational readiness through technician interviews and leadership alignment sessions, and finalize technology architecture decisions including edge-versus-cloud deployment models and MLOps platform selection. This foundation phase typically requires 400-600 engineering hours but prevents the costly false starts plaguing unprepared scaling attempts.
Weeks 1-4: Foundation
Data infrastructure assessment, integration architecture design, governance framework establishment, and initial site selection for wave-1 deployment
Weeks 5-8: Wave 1 Deployment
Deploy to 3-5 facilities, validate integration patterns, refine data pipelines, and document lessons learned for subsequent waves
Weeks 9-12: Wave 2 Expansion
Scale to 8-12 additional facilities using repeatable deployment playbooks, establish center of excellence, and demonstrate enterprise ROI
Week 13+: Full Rollout
Complete deployment across remaining facilities, optimize performance, and transition to continuous improvement mode
Days 31-60 execute wave-1 deployments to 3-5 carefully selected facilities representing diverse operational profiles. Site selection should include high-performing facilities with strong technical teams (establishing success patterns), challenging environments with integration complexity (stress-testing architecture), and representative average sites (validating scalability to broader deployment). Wave-1 deployment validates integration patterns, identifies unforeseen barriers, and generates early ROI demonstrations building executive confidence for continued scaling investment.
Days 61-90 accelerate deployment to 8-12 additional facilities using refined deployment playbooks documenting installation procedures, integration patterns, and troubleshooting protocols developed during wave-1. This phase establishes center-of-excellence teams providing specialized scaling expertise rather than requiring site-by-site custom development, implements automated deployment tooling reducing installation time by 40-60%, and generates comprehensive business value documentation quantifying aggregate ROI justifying full enterprise rollout.
Critical Success Factors for 90-Day Scaling
- Executive sponsorship with quarterly business reviews tracking scaling progress and ROI realization
- Dedicated scaling team (6-10 FTEs) focusing exclusively on deployment rather than splitting attention with pilot optimization
- Standardized deployment playbooks reducing site installation time from 600 hours to 150-200 hours
- Automated testing frameworks validating model performance before production cutover at each facility
- Change management infrastructure including technician training, support helpdesk, and feedback incorporation processes
- Performance monitoring dashboards providing real-time visibility into deployment status and business impact across all sites
Key metrics for scaling decisions extend beyond technical performance to encompass organizational readiness indicators, financial ROI validation, and operational impact assessment. Successful scaling requires demonstrating that wave-1 deployments achieve 80%+ of pilot performance levels, generate positive ROI within 12-18 months per site, maintain operational stability with <5% unplanned downtime increase during deployment, and earn 70%+ technician adoption rates indicating sustainable organizational acceptance rather than forced compliance.
Case Study: From Pilot Success to Enterprise Deployment
A $4.2 billion automotive components manufacturer provides compelling illustration of pilot-to-enterprise scaling transformation. Their predictive maintenance journey began with a promising pilot on high-speed stamping equipment achieving 94% failure prediction accuracy and preventing $680,000 unplanned downtime over nine months. Despite pilot success, the organization struggled for 14 months attempting to scale across 23 manufacturing facilities before recognizing fundamental architectural and governance deficiencies blocking progress.
Initial scaling attempts failed due to classic pilot purgatory symptoms: manual data preparation processes sustainable for single-line pilot but impossible to replicate across facilities, custom integration code tightly coupled to specific SCADA configurations preventing reuse, and absence of model monitoring infrastructure causing performance degradation going undetected for 4-6 months. After wasting $1.8 million on fragmented scaling efforts, leadership commissioned comprehensive scaling readiness assessment revealing systematic barriers requiring architectural transformation rather than incremental improvements.
Transformation Strategy Components
- Implemented unified data fabric standardizing sensor data collection, quality validation, and feature engineering across all 23 facilities
- Deployed containerized model deployment framework enabling consistent inference execution independent of local system configurations
- Established MLOps platform automating model versioning, testing, and performance monitoring across distributed deployments
- Created center-of-excellence team providing scaling expertise rather than site-by-site custom development
- Implemented comprehensive governance framework defining data quality standards, model performance requirements, and accountability structures
- Developed 90-day phased rollout strategy with wave-1 deployment to 5 facilities validating architecture before full-scale deployment
2025 AI Deployment Trends Transforming Scaling Success
- Local LLMs on NVIDIA GPUs enabling real-time predictive maintenance without cloud dependencies
- On-site AI deployments processing thousands of sensor signals in seconds for instant decision-making
- Edge computing eliminating data transfer costs and latency issues blocking cloud-based scaling
- Digital twin models combining condition data with virtual asset performance simulation
- Zero-trust security architectures keeping sensitive manufacturing data behind facility firewalls
- AI-powered diagnostic systems providing automatic fault identification with sub-second response times
- Seamless ERP and control system integration turning sensor data into actionable insights across operations
The transformed approach delivered dramatic results. Wave-1 deployment to 5 facilities completed in 11 weeks versus 18-month timeline for prior attempts, with deployment costs declining from $420,000 per facility to $145,000 through standardization and automation. Model performance maintained 88-93% accuracy across all deployments compared to 65-82% range in prior fragmented scaling attempts. Most significantly, the organization completed full enterprise deployment across all 23 facilities in 9 months following architecture transformation.
Business impact exceeded initial projections, with enterprise-wide predictive maintenance generating $12.4 million annual benefits through 42% unplanned downtime reduction, 35% maintenance cost optimization, and 18% overall equipment effectiveness improvement. The organization achieved positive ROI on total $4.7 million scaling investment (including architecture transformation costs) within 16 months, with ongoing benefits creating 3-year net present value exceeding $28 million.
Critical success factors identified in post-deployment analysis emphasized importance of executive sponsorship maintaining focus through architectural transformation period, dedicated scaling team avoiding distraction by competing priorities, and disciplined adherence to governance frameworks despite pressure for site-specific customizations. The organization now views its data infrastructure and deployment framework investments as strategic assets enabling rapid deployment of additional AI use cases leveraging established architecture rather than one-time expenses for single predictive maintenance application.
Conclusion
Predictive maintenance pilot scaling failure represents one of manufacturing's most expensive innovation traps, with 80% of GenAI projects never progressing beyond isolated successes while organizations waste millions on fragmented scaling attempts. The transformation from pilot purgatory to enterprise deployment requires recognizing that algorithm performance represents only 20-30% of scaling challenge—the remaining 70-80% involves data architecture, integration frameworks, governance structures, and organizational change management enabling reliable AI execution at scale.
Understanding systematic scaling barriers reveals that most pilot failures stem from architectural deficiencies rather than model quality limitations. Successful pilots operating in controlled environments with manual data preparation and simplified integration requirements encounter dramatically different challenges at enterprise scale, where brownfield system complexity, data quality variability, and organizational resistance across dozens of facilities demand sophisticated infrastructure and governance frameworks typically underestimated during pilot phase.
Comprehensive governance frameworks established before scaling attempts prove essential for sustained AI deployment success. Data quality standards, model performance requirements, change control procedures, and accountability structures prevent the technical debt accumulation and performance degradation that transform innovative pilots into unmaintainable systems requiring expensive rebuilds. Organizations implementing robust governance achieve 80-90% sustained model performance compared to 35-45% for those treating governance as administrative overhead.
Real-world case studies demonstrate the transformative impact of architectural investment and systematic scaling approaches. Organizations willing to invest 60-70% of scaling budgets in data infrastructure and governance frameworks—rather than allocating 80%+ to algorithm development—achieve 3-4x better deployment success rates and generate 4-6x higher returns through reliable enterprise-wide AI execution versus fragmented pilot expansion approaches.
The 2025 competitive environment increasingly rewards manufacturers successfully scaling AI deployments while penalizing those trapped in pilot purgatory. Success requires treating scaling as an architectural and organizational transformation challenge rather than incremental pilot expansion, investing systematically in infrastructure enabling reliable AI execution at enterprise scale, and establishing governance frameworks maintaining performance as deployments mature over multi-year lifecycles.
Ready to transform pilot success into enterprise-wide predictive maintenance dominance that generates $8-15M in sustained value?
The architectural frameworks and governance structures that move 92% accuracy pilots into facility-wide deployment aren't mystical—they're systematic, proven, and available right now. Stop wasting $2-4 million on fragmented scaling attempts that never escape pilot purgatory. Join the manufacturing leaders achieving enterprise AI deployment in 90 days rather than 24+ months of frustration.