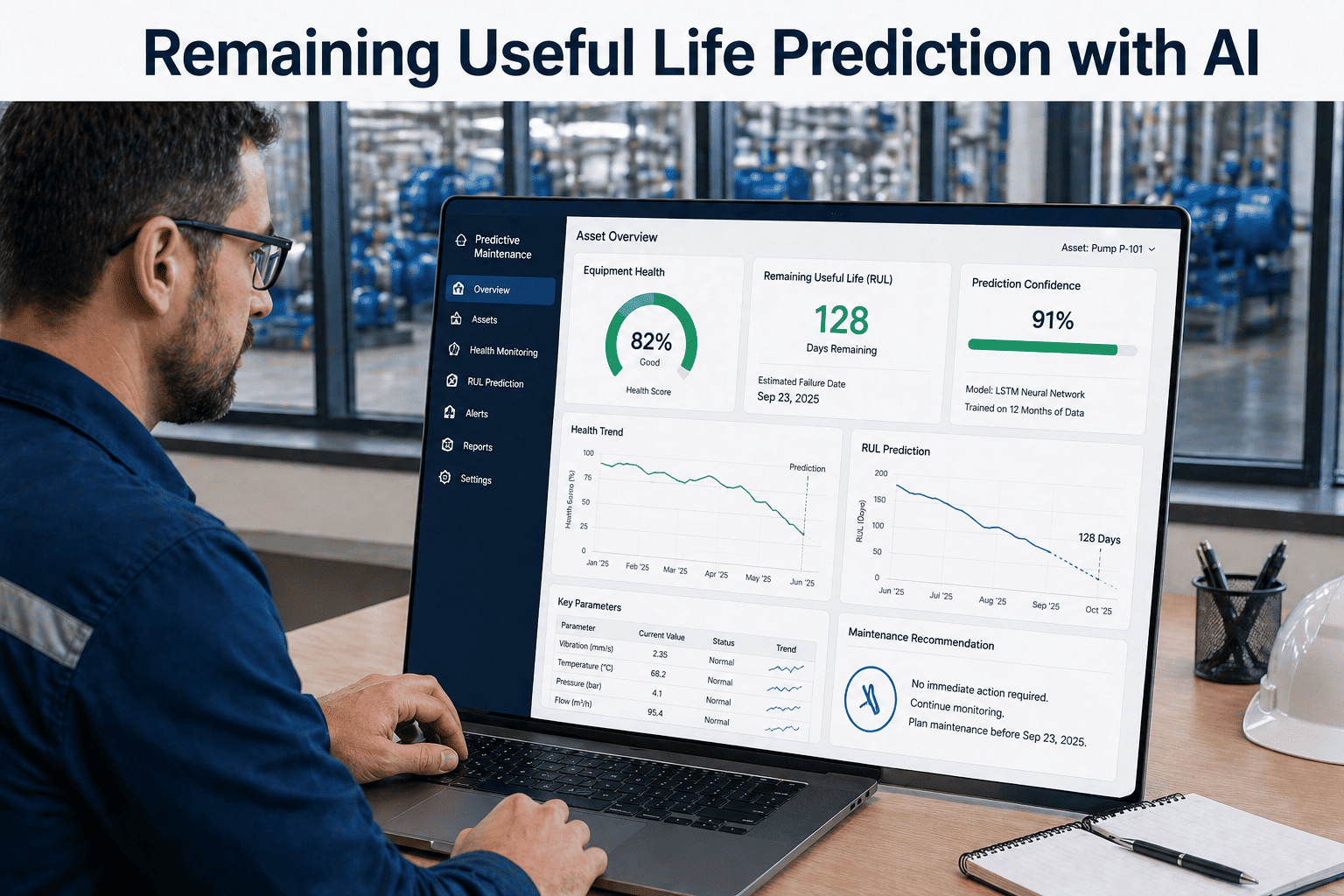
A modern industrial plant produces more sensor data in 24 hours than a 1990s factory produced in a year. A single high-frequency vibration sensor on a critical pump streams 25,600 samples per second — that is 2.2 billion data points per day per sensor. Multiply by 50 sensors across 200 critical assets and the math becomes uncomfortable: 22 terabytes a day. CPUs cannot analyze that in real time. GPUs can. NVIDIA's GPU-accelerated computing has quietly become the engine that turns predictive maintenance from a quarterly report into a real-time defense system. To see how OxMaint plugs into GPU-accelerated inference for your assets, you can start a free trial and run anomaly models on your own data within hours.
Industrial AI InfrastructureGPU AccelerationEdge Compute
NVIDIA GPU-Accelerated Predictive Maintenance: The Real-Time AI Stack for Industry
How GPU-powered deep learning processes terabytes of sensor data in milliseconds — turning predictive maintenance from a daily report into a real-time decision engine for plants, fleets, and infrastructure.
5,581FP4 teraflops on NVIDIA IGX Thor edge AI platform
200msEdge inference latency from sensor to decision
73%Drop in emergency repairs with GPU-driven prediction
$98BPredictive maintenance market projection by 2033
From sensor stream to work order — in milliseconds.OxMaint runs on GPU-accelerated AI so anomalies turn into action before failure happens.
Why CPUs Cannot Keep Up with Industrial Sensor Data
A modern predictive maintenance model — autoencoder, LSTM, or Transformer — performs millions of matrix operations per inference. CPUs do these sequentially. GPUs do them in parallel — thousands at a time. The result: a 50–200x speedup on the same model, meaning what took 4 seconds on a CPU runs in 20 milliseconds on a GPU. That is the gap between "yesterday's status" and "live decision." For asset-heavy industries, only one of those keeps assets running. To see GPU-accelerated PdM running on your data, you can book a demo with our solutions team.
Massive Parallelism
A single Blackwell GPU runs 16,000+ CUDA cores. Each core handles part of the model simultaneously — turning sequential math into parallel math.
Real-Time Inference
200 ms end-to-end from sensor input to anomaly score — 50–200x faster than CPU inference. Decisions happen in the moment, not in the morning report.
Edge Deployment
NVIDIA IGX Thor and Jetson run the trained model directly on the factory floor. No cloud round-trip. Data stays on-site, latency stays under 1 second.
Cloud Training Scale
DGX systems train deep models on years of historical failure data — work that would take months on CPUs completes in hours on GPU clusters.
The Architecture
The 6-Layer GPU-Accelerated Predictive Maintenance Stack
Layer 01
Industrial IoT Sensors
Vibration, thermal, acoustic, pressure, current — sampled up to 50 kHz. A single critical pump generates 1–4 GB of raw data per day across 8–12 sensors.
→
Layer 02
Edge GPU (Jetson / IGX)
NVIDIA IGX Thor — 5,581 FP4 TFLOPS, 400 GbE — runs trained models on-site. Inference under 200 ms. No data leaves the facility unless you choose.
→
Layer 03
Anomaly Scoring Pipeline
Autoencoder + classifier ensemble. Output: anomaly probability, failure-mode label, confidence band, remaining useful life. Updated every 60 seconds per asset.
→
Layer 04
DGX Cloud Training
DGX B200 systems retrain models nightly on aggregated multi-site data. Federated learning keeps tenant data isolated while improving the global model.
→
Layer 05
CMMS Decision Layer
OxMaint converts anomalies into prioritized work orders. Severity, parts list, technician dispatch — all auto-populated from model output.
→
Outcome
Closed-Loop Action
Technician executes, outcome captured, model retrained. The plant gets smarter every shift.
The Reality
Why CPU-Based Predictive Maintenance Hits a Wall
22 TB
Daily Data Volume
A 200-asset plant with high-frequency sensors generates 22 terabytes of raw data per day. CPU clusters take 6–12 hours to process — predictions arrive after the failure.
40–60 sec
CPU Inference Latency
Deep models on CPUs take 40–60 seconds per asset for inference. Multiply by 200 assets and the cycle exceeds 3 hours — too slow for live action.
5–8x
Cloud Bandwidth Cost
Streaming raw sensor data to the cloud costs 5–8x more than running inference at the edge. Bandwidth becomes the bottleneck before compute does.
11 weeks
Insight Lag
Industry average from "data captured" to "model retrained" on CPU pipelines is 11 weeks. By the time the model improves, the failure mode has already cost you.
CPU vs GPU
CPU-Based vs GPU-Accelerated Predictive Maintenance
Capability
CPU-Based PdM
NVIDIA GPU-Accelerated PdM
Per-asset inference latency
40–60 seconds
20–200 milliseconds
Sensor sampling rate supported
Up to 1 kHz practically
Up to 50 kHz with edge GPU
Daily data throughput per node
200–500 GB
20–40 TB
Model size feasible
Shallow ML, narrow features
Deep CNN / LSTM / Transformer
Edge deployment
Limited — slow inference
Native — IGX Thor & Jetson
Training time on 1 year of data
2–3 weeks
4–8 hours on DGX cluster
Real-time anomaly response
No — daily batch reports
Yes — sub-second to work order
Cost per inference
High labor + cloud spend
Sub-cent per inference at scale
The OxMaint Way
How OxMaint Connects to GPU-Accelerated AI
OxMaint does not require you to build a GPU stack. We integrate with NVIDIA's edge and data-center platforms — Jetson, IGX, DGX — through a unified data layer. Your sensors, your GPUs, our CMMS intelligence.
01
Edge Agent Deployment
Lightweight OxMaint agent installs on Jetson or IGX devices. Subscribes to your sensor stream and forwards features to the GPU model.
02
Pre-Trained Model Library
200+ asset categories ship pre-trained on millions of asset-hours. Tunes to your equipment in 30 days. No data scientist required.
03
Real-Time Anomaly API
GPU inference output flows into OxMaint via secure API. Anomaly score, failure mode, RUL update on each asset every 60 seconds.
04
Auto Work Order Engine
Anomalies above your action threshold create work orders with severity, recommended task, parts kit, and skilled technician assignment.
05
Federated Retraining
Model improves nightly using anonymized cross-site outcomes. Your data stays yours; the model gets smarter for everyone.
06
Portfolio Dashboard
Real-time view across every site, every asset class. CapEx forecasts and reliability metrics update with every inference cycle.
The Numbers
What GPU-Accelerated Predictive Maintenance Delivers
73%
Drop in emergency repairs in year one
94%
Anomaly detection accuracy with deep learning
8–14 days
Median early-warning window before failure
42%
Reduction in total maintenance spend
3.2x
Increase in MTBF on critical rotating equipment
11 mo
Average payback including hardware and software
If your plant is sitting on data your CPU stack cannot process, the upgrade path is shorter than you think. Book a demo for a sizing conversation.
FAQs
Frequently Asked Questions
Do we need NVIDIA DGX hardware to use OxMaint?
No. DGX is for large-scale model training. Most plants run inference on edge devices (Jetson, IGX) or on standard CPU servers for less data-intensive use cases. OxMaint scales from CPU-only deployments to GPU-accelerated edge clusters depending on your asset count and data volume.
Where does the model run — cloud, edge, or both?
Both. Training happens in the cloud (DGX or compatible) on aggregated historical data. Inference happens at the edge (IGX Thor / Jetson) for sub-second response. OxMaint orchestrates both paths so latency-sensitive decisions stay on-site while heavy training scales in the cloud.
How does data security work with cloud-trained models?
Federated learning. Your raw sensor data never leaves your perimeter. Only model gradients (anonymized) are shared during retraining cycles. The result: a globally improved model with locally controlled data. Compliant with most industrial cybersecurity frameworks.
What is the minimum GPU we need at the edge?
Jetson Orin NX (100 TOPS) handles up to 50 assets with high-frequency sensors. IGX Orin or IGX Thor scales to 500+ assets per node. OxMaint sizing tools recommend hardware based on your sensor mix and update cadence. Start a free trial to model your stack.
OxMaint runs on GPU-accelerated AI so anomaly detection, failure classification, and work-order generation happen in milliseconds — not in next month's report.