Multi-Site FMCG Maintenance Management: Standardizing Operations Across Plants
By Jason on March 12, 2026
FMCG manufacturers operating multiple production facilities face a maintenance management paradox: each site is unique enough to resist rigid uniformity, yet similar enough that fragmented, site-by-site approaches leave enormous value on the table. The best-performing site in a typical FMCG network operates at 40–60% lower maintenance cost per unit produced than the worst-performing site running identical equipment. That gap is not driven by asset differences — it is driven by the absence of standardised processes, shared knowledge, and cross-site visibility. This article sets out the framework for building an enterprise-wide maintenance programme that captures best-practice performance across every facility in your network, using Oxmaint's Multi-Site Management and Enterprise Dashboard capabilities as the operational backbone.
Managing maintenance across multiple FMCG sites?
Oxmaint's Multi-Site Management and Enterprise Dashboard give you unified visibility, standardised processes, and cross-site benchmarking — from a single platform.
Performance Gap Between Best and Worst Site in a Typical FMCG Network
68%
of FMCG Multi-Site Operations Have No Unified Maintenance KPI Framework
$1.4M
Average Annual Saving When Best-Practice Is Propagated Across a 5-Site Network
24mo
Typical Timeline to Full Network Standardisation and Measurable Cost Reduction
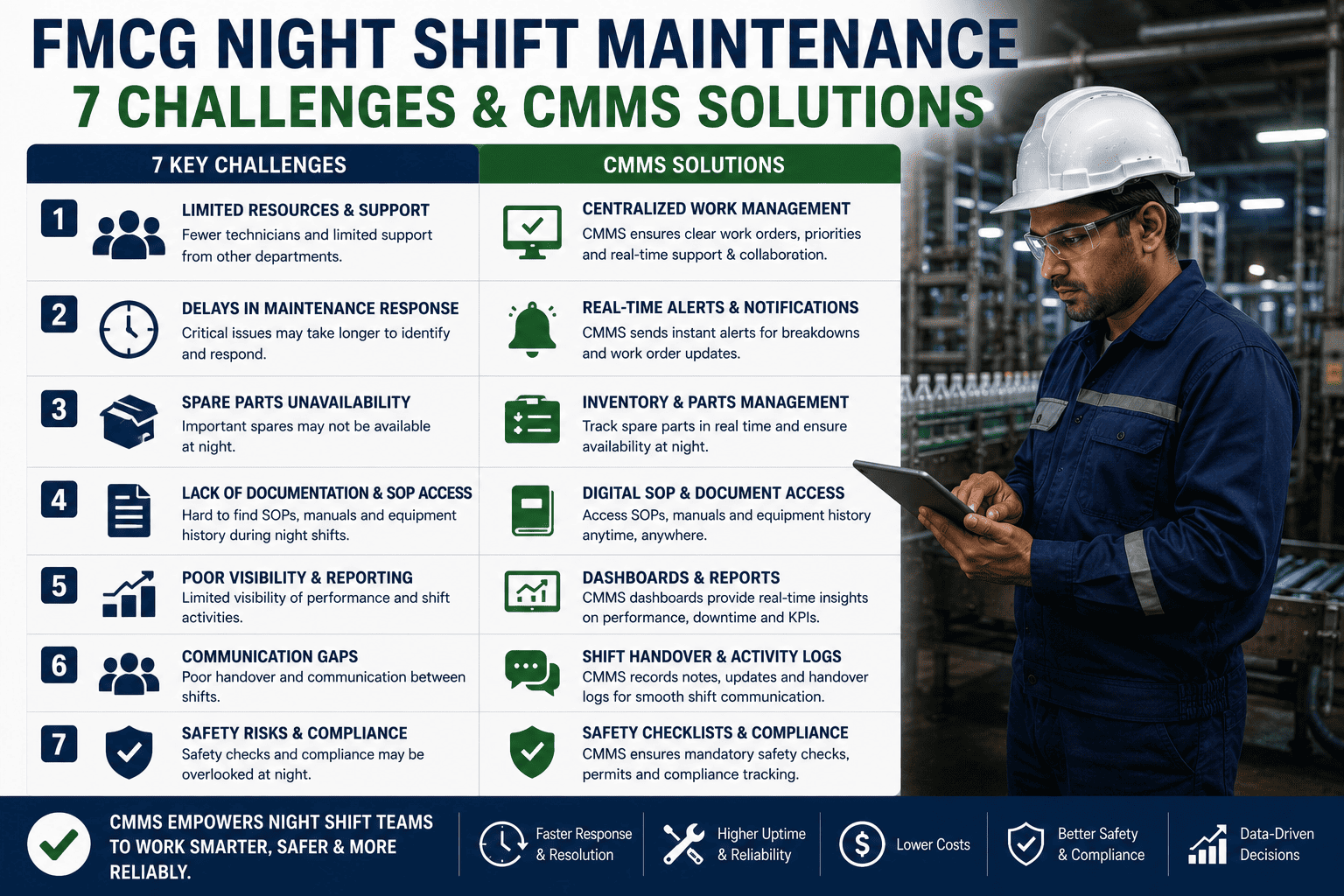
Why Multi-Site FMCG Maintenance Fails Without Standardisation
The natural state of a growing FMCG maintenance operation is fragmentation. Sites are acquired, built, or inherited with different asset bases, different local CMMS platforms, different technician training histories, and different maintenance cultures shaped by whoever ran the operation before group oversight arrived. Left unmanaged, this fragmentation compounds: each site develops its own work order coding, its own PM interval logic, its own parts procurement habits, and its own definition of what constitutes an acceptable downtime event. By the time the group maintenance director tries to compare performance across the network, the data is incomparable.
Six Failure Modes of Uncoordinated Multi-Site FMCG Maintenance
Incomparable Performance Data
Sites use different work order categories, different downtime definitions, and different KPI calculations — making meaningful cross-site comparison impossible and leaving performance gaps invisible to group leadership
Siloed Best Practice
The best PM interval for a filling machine carousel bearing was discovered at Site 2 three years ago — but Sites 4, 5, and 6 still use the manufacturer's default interval and are paying for the failures that follow
Duplicated Parts Inventory Across Sites
Each site maintains its own spare parts stock independently — critical components held in expensive local inventory at every site simultaneously, while another site pays emergency procurement premiums for the same part it could have borrowed from a neighbour
No Network-Level Contractor Leverage
Sites negotiate specialist contractor rates individually — paying local market rates rather than the volume-based rates achievable through a single network-wide supplier framework covering all sites simultaneously
Technician Skills Not Transferable Across Sites
Each site's training programme produces technicians who understand local procedures and local systems — not standardised processes that would allow skilled technicians to work effectively across the network during shutdowns, peaks, or emergencies
Group Leadership Flying Blind
Group maintenance directors receive lagged, inconsistent monthly reports from each site — no real-time network visibility, no ability to identify emerging problems before they become crises, and no data to support capital allocation decisions across the portfolio
The Multi-Site Standardisation Framework: Five Pillars
Effective multi-site maintenance standardisation is not about imposing identical procedures on every facility regardless of context — it is about establishing the common infrastructure that makes performance visible, comparable, and improvable across the network. The five-pillar framework below defines what must be standardised (data, KPIs, asset taxonomy, PM logic, and reporting) and what should remain locally adapted (specific intervals calibrated to local operating conditions, technician skill mix, and site-specific safety requirements).
The prerequisite for all other pillars. Every asset across every site must be classified using a consistent taxonomy — same asset type codes, same location hierarchy, same work order categories, same failure mode classifications. Without this, data from different sites cannot be aggregated, compared, or used to build network-level AI models. A unified taxonomy does not mean every site has the same assets — it means every site describes its assets in the same language.
Standard asset type hierarchy — Equipment Class → Sub-Class → Asset → Component
Unified work order categories — PM, CM, Emergency, Inspection, Project — consistently applied across all sites
Standard failure mode library — same fault codes for the same failure types across all sites and asset classes
Consistent downtime definition and recording — start/end time, production impact, root cause category
Enables: Cross-site data aggregation, network-level AI models, meaningful benchmarking
P2
Shared KPI Framework with Site-Level Accountability
A shared KPI framework defines the metrics used to measure maintenance performance consistently across every site — so that a site manager's MTBF figure means exactly the same thing as the group director's MTBF figure on the enterprise dashboard. The framework must be simple enough to be operationally meaningful at site level but comprehensive enough to give group leadership the visibility they need for portfolio decisions.
MTBF and MTTR — calculated consistently per asset class across all sites, not just per incident
PM Compliance Rate — planned PM tasks completed on time as a % of total scheduled, per site per period
Reactive Maintenance % — emergency and unplanned work orders as % of total, tracked monthly per site
Maintenance Cost per Unit Produced — total maintenance spend divided by production output, enabling like-for-like site comparison
OEE per Line — availability × performance × quality, reported consistently across the network
Enables: Site ranking, performance accountability, capital allocation decisions
P3
Enterprise-Wide PM Programme with Local Calibration
The enterprise PM programme defines the maintenance activities required for each asset class — what tasks, at what frequency, with what method — as a network-wide standard derived from the best-performing site's approach. Local sites can adjust intervals based on actual operating conditions (run hours, product types, environmental factors) but cannot remove tasks from the standard programme without engineering justification. This creates consistency of approach while preserving the flexibility needed for genuine operating condition differences.
Master PM task library — standard task descriptions, durations, and skill requirements per asset class, managed centrally
Interval governance — group-set default intervals with documented local override process requiring engineering sign-off
Condition-based trigger propagation — AI-derived condition thresholds from high-data sites shared as starting points for lower-data sites
PM effectiveness review cycle — quarterly cross-site review of PM compliance vs. failure rates to validate interval decisions
Enables: Consistent asset care, knowledge transfer, interval optimisation across the network
P4
Centralised Reporting and Real-Time Enterprise Dashboard
Group leadership cannot manage what they cannot see. A centralised enterprise dashboard that aggregates real-time performance data from all sites — replacing lagged monthly spreadsheet reports — transforms the group maintenance director from a reactive administrator into a proactive portfolio manager. The dashboard must present the right information at the right level of aggregation: network summary for the group director, site detail for the plant manager, asset-level drill-down for the reliability engineer.
Network-level OEE, downtime, and maintenance cost — live, not monthly
Site performance ranking on shared KPIs — updated daily, accessible to all site managers simultaneously
Exception flagging — automated alerts when a site's KPI drops below network average threshold
Asset health status across the network — critical assets flagged for attention regardless of which site they are on
Budget vs. actual maintenance spend per site — live tracking against annual maintenance budgets
Enables: Proactive group leadership, early intervention, capital allocation confidence
P5
Structured Knowledge Sharing and Best-Practice Propagation
The highest-value output of a multi-site maintenance programme is the systematic identification and transfer of what the best-performing site is doing differently — to every other site in the network. This does not happen automatically through a shared CMMS: it requires a deliberate governance process that regularly reviews cross-site performance data, identifies the practices behind best performance, documents them in standardised work procedures, and deploys them as updates to the enterprise PM library accessible to all sites.
Quarterly cross-site reliability review — structured meeting comparing site performance, identifying outliers (positive and negative)
Best-practice documentation process — standard format for capturing and validating site-derived improvements before network deployment
Enterprise PM library version control — changes to standard PM procedures versioned, approved, and pushed to all sites via CMMS
Cross-site technician exchange programme — structured visits enabling hands-on knowledge transfer between sites on specific asset types
Benchmarking only has value if the metrics being compared are calculated identically across every site. The table below defines the benchmark ranges for each KPI across the shared framework — what a high-performing site achieves, what an average FMCG site achieves, and the improvement levers that close the gap. Book a demo to see how Oxmaint's Enterprise Dashboard surfaces these metrics in real time across your network.
The gap between average and high-performing sites on every KPI above is not explained by equipment differences — it is explained by process maturity, data visibility, and the systematic application of condition-based maintenance principles. Standardisation closes it.
Enterprise CMMS Deployment: The 24-Month Roadmap
Deploying a unified CMMS across a multi-site FMCG network is the enabling infrastructure for all five standardisation pillars. The roadmap below is drawn from Oxmaint's multi-site implementation experience across FMCG networks of 3–22 facilities, and represents the sequencing that minimises disruption while maximising speed to measurable value. Start your free trial to explore how Oxmaint structures enterprise deployment for your specific network configuration.
Enterprise PM task library built — standard tasks per asset class, intervals derived from best-performing site data
PM programme deployed network-wide via Oxmaint — legacy calendar schedules retired on asset-by-asset basis
IoT sensors deployed on critical assets at all sites — vibration, temperature, and current monitoring live
Condition-based PM triggers activated — AI anomaly detection running on sensor data from all sites simultaneously
Spare parts inventory consolidated — network-level visibility into parts availability, inter-site transfer process established
Milestones
Month 6 — Enterprise PM library live at all sites, PM compliance tracking active
Month 8 — First AI-predicted failures averted at 3+ sites — ROI evidence established
Month 10 — First best-practice propagation: high-performing site interval adopted network-wide
Month 12 — Mid-programme review: reactive maintenance % down across all sites, first cost savings confirmed
Phase 2 Output: Standardised PM programme running across the network — performance variation beginning to compress as best practice spreads
Phase 3 — Months 13–24: Optimisation
Continuous Improvement, Network Learning & Full ROI
Activities
Quarterly cross-site reliability reviews institutionalised — structured format, standard agenda, action tracking via CMMS
Network AI models maturing — failure prediction accuracy improving as cross-site data volume grows
PM intervals continuously optimised — condition data from all sites informing interval adjustments for each asset class
Contractor framework renegotiated — network volume leverage used to secure improved rates and SLAs
Enterprise dashboard live for group board — maintenance cost, OEE, and reliability metrics in executive reporting format
Milestones
Month 15 — Network performance variation reduced by 40% vs. baseline
Month 18 — All sites within 20% of best-site performance on primary KPIs
Month 20 — Enterprise contractor framework in place — network-rate agreements signed
Month 24 — Full programme audit: 40–60% cost gap closed, $1.4M+ annual saving confirmed across 5-site network
Phase 3 Output: Network operating as a learning system — every improvement at any site propagated to all sites within one review cycle
Oxmaint Multi-Site Management Capabilities
Oxmaint's Multi-Site Management and Enterprise Dashboard are built specifically for FMCG networks operating multiple facilities — connecting every site's maintenance data into a single platform that gives group leadership the visibility and site managers the tools to deliver continuous improvement. Start your free trial to explore the full capability set, or book a demo to see multi-site deployment in action.
Real-time OEE, downtime, maintenance cost, and KPI tracking across all sites in a single view — accessible to group leadership, site managers, and reliability engineers at the appropriate level of detail
Unified Asset Register
Single asset taxonomy across all sites — consistent classification, location hierarchy, and asset attributes enabling meaningful network-level performance analysis and cross-site comparisons
Cross-Site KPI Benchmarking
Automated calculation and ranking of shared KPIs across all sites — MTBF, MTTR, PM compliance, reactive %, OEE, and cost per unit all calculated identically, updated daily, visible to all stakeholders
Enterprise PM Library
Centrally managed standard PM task library — maintenance procedures, intervals, and skill requirements defined at network level, deployed to all sites via CMMS with version control and approval workflow
Network Parts Inventory
Consolidated spare parts visibility across all sites — real-time stock levels, inter-site transfer capability, and network-level reorder management eliminating duplicate holding and reducing emergency procurement
Network AI Models
AI failure prediction models trained on cross-site data — assets with limited individual site history benefit from failure patterns detected across the network, improving prediction accuracy at every site simultaneously
Best-Practice Propagation
Structured workflow for identifying high-performing site practices, documenting them as standard procedures, and deploying them network-wide — closing the performance gap systematically rather than hoping it happens organically
Group & Site Reporting
Automated reporting at every level — site daily reports, group weekly summaries, board monthly packs — all generated from the same data source with no manual aggregation or spreadsheet preparation required
Frequently Asked Questions
Standardisation operates at two levels: infrastructure (data taxonomy, KPI definitions, reporting formats) must be identical across all sites to enable comparison; content (specific PM intervals, task sequences, condition thresholds) should be standardised at the asset class level but calibrated to local operating conditions. A filling machine is a filling machine — the maintenance tasks are the same whether it is at Site 1 or Site 6. What differs is the interval, which should reflect actual run hours, product type, and environmental conditions at each site. Oxmaint's enterprise PM library enables central task management with local interval adjustment governance.
The most effective governance structure for a 3–10 site FMCG network has three tiers: (1) a Group Maintenance Director or Network Reliability Manager who owns the enterprise PM library, the shared KPI framework, and the quarterly cross-site review process; (2) Site Maintenance Managers who are accountable for site-level KPI performance and local PM compliance; and (3) an Asset Class Lead for each major equipment type (filling, packaging, utilities, CIP) who is responsible for identifying best practice on their asset class and maintaining the relevant PM task standards across the network.
The first meaningful cross-site KPI comparison is typically available within 6–8 weeks of Oxmaint enterprise deployment — once all sites are on the platform and work orders are being recorded consistently, the shared KPI calculation runs automatically. The comparison becomes statistically robust at 3 months of consistent data. Historical data can be migrated to extend the baseline, but even without migration, the 3-month live data is sufficient to identify the performance gaps between sites that drive the initial improvement programme.
Resistance to standardisation at site level is almost always driven by one of two concerns: that the standard approach does not fit local conditions, or that standardisation reduces local autonomy in ways that undermine operational effectiveness. Both are legitimate concerns that require a governance response rather than a mandate. The most effective approach is to give sites visibility of their own performance relative to the network — site managers who can see they are 40% above network-average maintenance cost per unit are typically strongly motivated to understand and adopt what the better-performing sites are doing. Oxmaint's benchmarking dashboard creates this visibility automatically.
Yes. Oxmaint supports integration with SAP PM, Maximo, Oracle EAM, and most major ERP systems — enabling sites to maintain ERP financial integration while transitioning maintenance operations to the Oxmaint enterprise platform. For sites with legacy local CMMS, Oxmaint's implementation team provides data migration tooling and historical record digitisation support. The typical transition approach is to run Oxmaint as the primary work order and maintenance management system from Day 1, with ERP integration handling procurement and cost allocation in the background.
Multi-Site FMCG Maintenance Management
Standardise Maintenance Across Every Plant. Close the 40–60% Performance Gap.
Oxmaint's Multi-Site Management and Enterprise Dashboard connect every site's maintenance data into a single platform — giving group leadership real-time network visibility and site managers the tools to deliver consistent, improving performance.
$1.4M
Average Annual Saving — 5-Site FMCG Network
24mo
To Full Network Standardisation
60%
Performance Gap Closed
5 Pillars
Standardisation Framework
✓Enterprise Dashboard — real-time OEE & cost across all sites
Oxmaint Multi-Site Management supports FMCG networks from 2 to 50+ facilities. Full implementation support and data migration included. Results visible within 90 days of network go-live.