AI Infrastructure Roadmap 2026: Build, Buy, or Subscribe?
By Riley Quinn on May 1, 2026
Loading...
Every U.S. manufacturer making an AI infrastructure decision in 2026 is staring at the same three doors: build a private GPU cluster, subscribe to a cloud API, or buy a managed AI platform. Pick the wrong door and you'll spend 18 months and $2M learning a lesson your competitor already paid for. Pick the right one and AI becomes your fastest path to operational advantage — reduced downtime, leaner maintenance budgets, and machines that tell you when they're about to fail. This guide maps the real decision framework: when to build, when to buy, and when to subscribe — with a 5-year infrastructure lens built for manufacturing operations. Start mapping your AI infrastructure with OxMaint — free account, no setup required.
SAP SAPPHIRE ORLANDO · MAY 12, 2026
Meet OxMaint at SAP Sapphire 2026 — Map Your AI Infrastructure Path Live
Join us in Orlando to model your exact AI infrastructure architecture — cloud API subscription, on-prem GPU cluster, or hybrid edge deployment. Walk in with your asset count and OT constraints; walk out with a costed, defensible 5-year plan.
Build vs. Buy vs. Subscribe cost modeling demo
GPU cluster vs. edge AI vs. managed SaaS breakeven analysis
Own Your AI — Infrastructure Architecture for Modern Manufacturing
The 2026 Inflection Point: Inference costs have dropped 280x in two years — yet enterprise AI spending is still rising. The reason: usage has outpaced cost reduction. Manufacturers who chose their AI infrastructure model in 2023 are re-evaluating now. This guide shows you what to change — and what to keep.
Why the 2026 AI Infrastructure Decision Is Different from 2023
Three years ago, most manufacturers had only one real option: subscribe to a cloud AI vendor and accept their constraints. Today the landscape has inverted. See how OxMaint deploys AI-driven maintenance across cloud, edge, and hybrid environments — start free. Open-source AI ecosystems have matured, edge hardware has commoditized, and the regulatory environment has tightened enough that data sovereignty is no longer just a concern for defense contractors. The three-way decision — build, buy, or subscribe — now has genuinely different economics depending on your plant scale, OT network structure, and asset complexity.
Inference Costs Collapsed
Cloud API costs per inference dropped 280x in two years. Subscriptions that were cost-prohibitive at scale are now viable for mid-size plants — but per-query billing still penalizes high-frequency monitoring.
Edge Hardware Is Commodity
NVIDIA Jetson-class edge GPUs and ARM-based ML accelerators have dropped below $800 per node. Building on-prem is no longer just for enterprises with a 6-person data science team and a $5M budget.
Regulation Is Real Now
EU AI Act high-risk provisions take full effect August 2026. U.S. regulated manufacturers in pharma, defense, and food face new data residency and audit requirements that cloud-only architectures may not satisfy.
Talent Gap Is Widening
38% of enterprises cite skill gaps as a top-3 barrier to AI scale. Most manufacturing plants don't have ML engineers on staff — which shapes which architecture is actually sustainable, not just theoretically optimal.
The Three Paths: Build, Buy, Subscribe — What Each Actually Means
Before you can make the decision, you need a clear-eyed definition. These terms get used interchangeably, and that confusion costs plants real money when they commit to the wrong model.
01
BUILD
On-Prem GPU Cluster or Edge AI
You own the hardware, train the models on your asset data, and run inference locally. Full control. Full responsibility.
You purchase a pre-built AI platform — sensors, models, and dashboards included. Vendor manages infrastructure; you manage operations.
Upfront Cost
$10K – $150K
Setup Time
Days to weeks
Team Required
Reliability engineer only
Fast deploymentCMMS integrationLow technical liftVendor dependencyLimited customization
03
SUBSCRIBE
Cloud API (Consumption-Based)
You call a cloud AI API per inference — OpenAI, AWS, Azure. Zero hardware. Zero training. Pure pay-per-use consumption.
Upfront Cost
Near zero
Setup Time
Hours to days
Team Required
Developer + IT
Instant startNo hardwareCost scales with volumeData leaves plantCloud latency
Not Sure Which Path Fits Your Plant?
OxMaint operates across all three models — managed platform, edge AI integration, and hybrid deployments. Our team will map your asset count, OT network, and maintenance team profile to the right infrastructure model in 30 minutes.
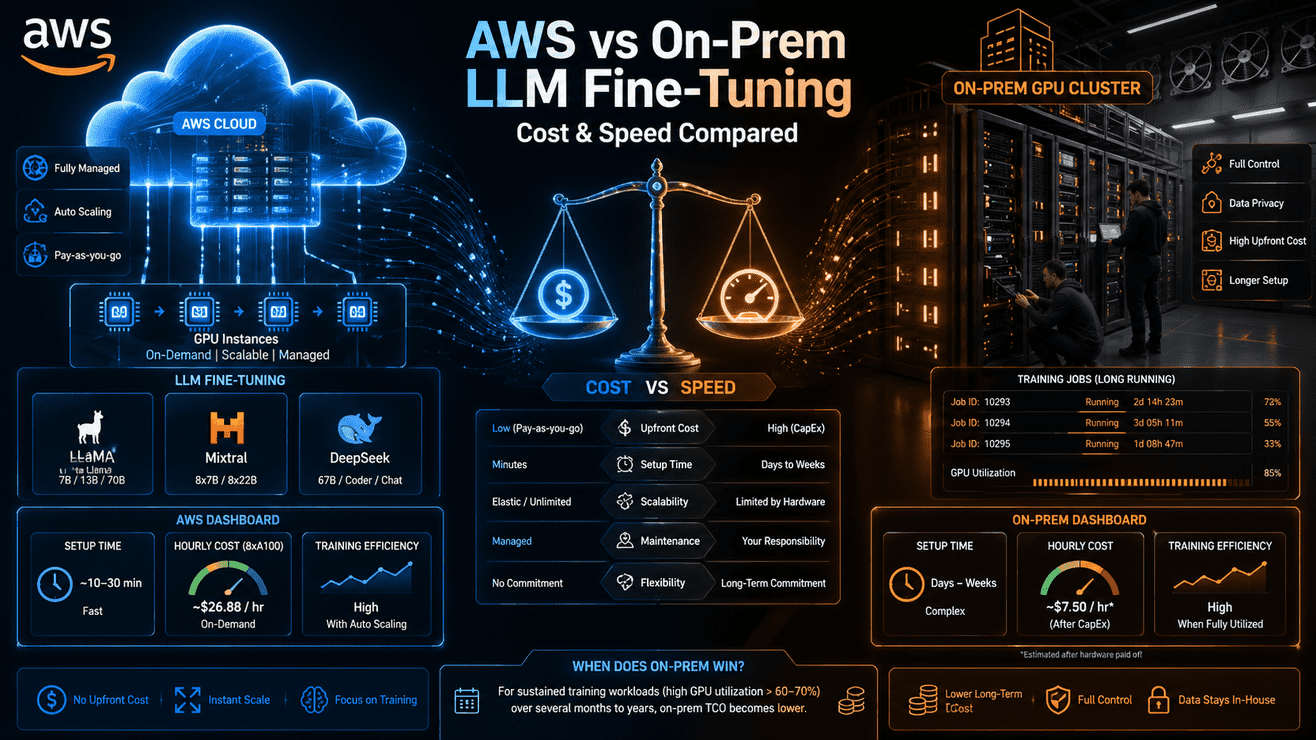
5-Year Cost Comparison: What Each Model Actually Costs at Scale
The build vs. buy vs. subscribe debate always looks different on paper than it does on a 5-year P&L. The numbers below reflect a representative mid-size U.S. manufacturing plant with 150 monitored assets. Your numbers will vary — but the structure of the cost curves is the same across plant sizes.
5-Year Total Cost of Ownership — 150 Monitored Assets
Illustrative model · Actual costs vary by vendor, hardware, and team configuration
Year 1Year 2Year 3Year 4Year 55-Yr Total
Build (On-Prem)
$620K
$130K
$130K
$130K
$130K
$1.14M
Subscribe (Cloud API)
$175K
$240K
$310K
$385K
$475K
$1.585M
Buy (Managed Platform)
$235K
$150K
$150K
$150K
$150K
$835K
Year 1 CAPEX dominates Build. Subscribe costs escalate as inference volume grows. Managed platforms deliver the lowest 5-year TCO for plants under 300 assets — with lowest execution risk.
The Decision Matrix: Which Architecture Wins for Your Plant Profile
Match your plant profile to the right deployment model
Plant Characteristic
Build (On-Prem)
Buy (Managed)
Subscribe (Cloud)
Asset Count
300+ assets
50–300 assets
Under 100 assets
OT Network Policy
Air-gapped / classified
Managed OT/IT separation
Requires cloud access
Data Sovereignty
All data on-site
Hybrid — configurable
Data exits plant
Alert Latency Req.
Milliseconds (edge inference)
Seconds (local processing)
Minutes (cloud roundtrip)
ML Team In-House
Required (2–4 FTE)
Not required
1 developer needed
Custom Failure Models
Full customization
Vendor-guided tuning
Black-box generic models
Time to First Alert
6–18 months
Days to weeks
Hours to days
CMMS Integration
Custom API build
Native connectors
Manual or custom dev
5-Year TCO (150 assets)
$1.14M
$835K
$1.585M
Regulatory Compliance
Highest control
Vendor-certified
Shared responsibility
The 5-Year AI Infrastructure Roadmap: Phase by Phase
Committing to an AI infrastructure model isn't a single decision — it's a staged journey. Get OxMaint's AI-ready maintenance platform deployed in days, not months — try free. Most manufacturing plants fail at AI not because they chose the wrong technology, but because they jumped to Phase 3 without finishing Phase 1. Here is the right sequence.
Phase 1
Months 1–3
Readiness Assessment
Audit your data maturity, OT network topology, team skills, and asset failure history. Map which assets actually need AI monitoring vs. which are stable enough for scheduled PM. Define what "success" looks like numerically — target OEE, downtime reduction %, MTBF improvement.
Deliverable: Asset-by-asset AI priority map + infrastructure model shortlist
Phase 2
Months 3–6
Pilot — Subscribe or Buy First
Deploy AI monitoring on 10–20 critical assets using a managed platform or cloud API. Prove the ROI loop — alert generated → work order created → failure prevented. Collect real asset failure data from your plant. This data becomes the training foundation if you later move to a build model.
Deliverable: Documented ROI case with real prevented-failure cost savings
Phase 3
Months 6–12
Expand + Integrate
Scale from pilot to plant-wide deployment. Connect your AI alerting layer to your CMMS — this is where most ROI is lost. Without auto-generated work orders, you're paying for alerts that get ignored. Set up MLOps pipelines for model monitoring and retraining as new failure data comes in.
Deliverable: Full plant coverage + CMMS auto-work-order pipeline live
Phase 4
Year 2
Optimize the Architecture
Evaluate the 60-70% rule: when cloud API costs reach 60–70% of equivalent on-prem costs, the economics of repatriation tip in your favor. Route high-frequency, safety-critical assets to edge inference. Keep lower-priority periodic monitoring on cloud APIs. Hybrid is almost always the right long-term answer.
Deploy agentic AI that doesn't just alert — but autonomously routes maintenance priorities, pre-orders parts, and adjusts PM intervals based on real-time asset health. The agentic AI market is projected at $8.5B in 2026 and $45B by 2030. Plants that built the sensor-to-CMMS loop in Phase 3 are the only ones ready for this.
Deliverable: Autonomous maintenance loop — from anomaly to resolved work order
Expert Perspective: The Architecture Trap Most Plants Fall Into
The costliest mistake I see manufacturing teams make in 2026 isn't picking the wrong infrastructure — it's building before they have data. A plant that spends $800,000 on a private GPU cluster before running a 90-day pilot has essentially bought an expensive classroom. You need real failure data from your own assets before a custom model can outperform a managed platform. Start with a managed buy or a cloud subscription. Get the data. Prove the loop — alert to work order to fix. Then, and only then, does a build model make financial sense for most manufacturers. The second trap is treating CMMS integration as a Phase 3 problem. It has to be Phase 2. An alert that doesn't auto-generate a work order doesn't prevent downtime. It just notifies someone who may or may not act on it that same shift.
Data Comes Before Models
50% of enterprise AI initiatives fail to reach production because the underlying data infrastructure isn't ready. Audit your historian, sensor coverage, and failure records before choosing an architecture.
The 60-70% Repatriation Rule
Once cloud API costs reach 60–70% of equivalent on-prem costs at your usage volume, the economics of moving workloads in-house tip in your favor. Track this number quarterly from Year 2 onward.
Governance Can't Be an Afterthought
EU AI Act high-risk requirements, U.S. data residency rules, and internal audit obligations are real infrastructure costs — not just compliance checkboxes. Factor them into your architecture cost model from Day 1.
2026 Market Stats: Where AI Infrastructure Investment Is Flowing
$100B
Sovereign AI compute investment expected by end of 2026 — nations building data sovereignty infrastructure
Source: Industry analysts 2026
280x
Decline in per-inference cloud AI costs over the last two years — making subscriptions viable for mid-size plants
Deloitte Tech Trends 2026
$8.5B
Agentic AI market size in 2026 — growing to $45B by 2030 as autonomous maintenance loops mature
Market research 2026
60%
Of agentic AI projects projected to fail in 2026 due to lack of AI-ready data pipelines and infrastructure
Gartner 2026 Prediction
Connect Your Assets to AI-Driven Maintenance — Today
OxMaint is the managed AI maintenance platform built for manufacturers who need to move fast without building custom infrastructure. Condition monitoring, auto work orders, and CMMS integration — live in days, not quarters.
Conclusion: The Right Infrastructure Is the One You'll Actually Use
The 2026 AI infrastructure decision for manufacturing isn't a technology debate — it's an operations strategy. Build only when you have the data, the team, and the scale to justify the CAPEX. Subscribe when you're validating ROI and moving fast. Buy a managed platform when you need predictable costs, CMMS integration, and a reliability team that can operate it without ML engineers. The 5-year roadmap is clear: start with a managed model, build your data foundation, prove the alert-to-work-order loop, then optimize your architecture around the workloads that justify on-prem compute. Most manufacturers will land in a hybrid model by Year 3 — not because hybrid is always best, but because different assets have genuinely different latency, data sovereignty, and cost requirements. See how OxMaint closes the gap from AI alert to fixed machine — book your architecture demo. The math is unchanged: every dollar invested in condition monitoring returns seven. The question is whether your infrastructure lets that dollar flow back — or traps it in alert notifications that never became work orders. Start your free OxMaint account and connect your first 10 assets today.
Frequently Asked Questions
What is the difference between build, buy, and subscribe for AI infrastructure in manufacturing?
Build means you own and operate on-premises GPU hardware and train AI models on your own data — full control, highest upfront cost. Buy means you purchase a managed AI platform where the vendor provides the models, sensors, and software as an integrated solution you operate. Subscribe means you call cloud AI APIs on a per-inference consumption basis — lowest upfront cost, but costs scale with usage volume and data must leave your plant. Most manufacturers should start with a buy or subscribe model, prove ROI, then evaluate whether on-prem build economics make sense at their scale.
When does it make sense to build an on-premises AI infrastructure for a manufacturing plant?
On-prem build makes economic and operational sense when three conditions align: you have 300+ assets requiring continuous high-frequency monitoring, your OT network is air-gapped or has strict data sovereignty requirements that prevent cloud routing, and you have in-house ML engineers or reliability engineers capable of managing custom model training and retraining. Plants with fewer assets or no data science team almost always see better ROI from a managed buy model. Never build before you have 12+ months of real asset failure data from your own plant — without it, a custom model can't outperform a general-purpose managed platform.
What is the 60-70% repatriation rule for AI infrastructure costs?
The 60-70% rule is a practical breakeven benchmark used by infrastructure teams to evaluate when to move AI workloads from cloud APIs to on-premises hardware. When your monthly cloud API inference costs reach 60-70% of what equivalent on-prem compute would cost at the same volume — accounting for hardware amortization, power, and maintenance — the economics of repatriation begin to favor moving workloads in-house. Manufacturing plants running continuous vibration monitoring on 200+ assets often hit this threshold by Year 2-3 of a cloud subscription. Review this ratio quarterly starting in Year 2 of your AI deployment.
How does CMMS integration affect AI infrastructure ROI?
CMMS integration is the single largest variable in AI infrastructure ROI — more than the infrastructure model itself. An AI alert that requires a technician to manually log into a separate system, create a work order, assign a technician, and order parts loses 60-80% of its value to that friction. When vibration or condition monitoring AI connects directly to a CMMS to auto-generate work orders, the entire maintenance loop closes automatically — anomaly detected, work order created, technician dispatched, parts pre-ordered. Plants with native CMMS integration see ROI confirmation within 12 months. Plants without it often fail to prove ROI at all, regardless of how accurate the AI models are.
What does a realistic 5-year AI infrastructure roadmap look like for a mid-size manufacturer?
A realistic 5-year roadmap for a 150–300 asset manufacturing plant follows five phases: Phase 1 (months 1-3) is a readiness assessment — auditing data quality, OT network topology, and team skills. Phase 2 (months 3-6) is a pilot using a managed buy or cloud subscribe model on 10-20 critical assets, focused on proving the alert-to-work-order-to-fix loop. Phase 3 (months 6-12) is plant-wide expansion with full CMMS integration. Phase 4 (Year 2) is architecture optimization — evaluating hybrid routing where high-frequency safety-critical assets move to edge inference while periodic monitoring stays on cloud APIs. Phase 5 (Years 3-5) is agentic AI deployment, where autonomous maintenance loops replace manual work order creation entirely. Most plants land on a hybrid model by Year 3.